

ETL vs ELT and the Modern Data Stack 2026 Best?
Most data teams still consider ETL vs ELT as one and the same thing, but these terms actually refer to two very different ways of working with data. Knowing the difference is the main thing when it comes to building a data stack that is both up-to-date and can be expanded with ease.
What are ETL and ELT?
- ETL (Extract–Transform–Load): The data is taken from the sources, the dirty work of transforming is done on the separate compute layer or the ETL tool, and the data warehouse is made ready by loading the data in a cleaned/reshaped form. This procedure is typical of on-prem warehouses, which are storage limited.
- ELT (Extract–Load–Transform): Data is extracted and loaded almost “as is” into a warehouse or a data lake, and the changes are made inside the warehouse with the help of its compute engine (usually SQL + orchestration tools).
For a lot of teams, ELT has pretty much become the standard way of working in the cloud world of data, as warehouses can cheaply store raw data and are powerful enough to carry out most of the transformations.
Connect With Us: WhatsApp
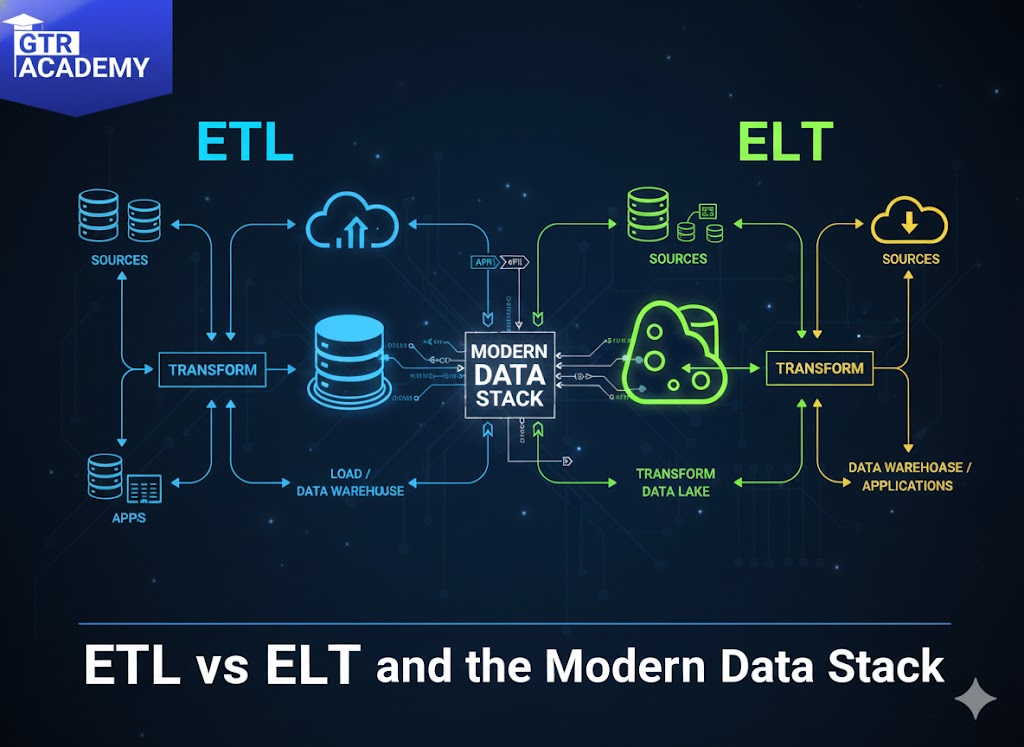
Why ELT is the leading technology in the modern data stack
The likes of Snowflake, Big Query, Redshift, Databricks, and other modern cloud data warehouses, are not only good for large scale computations but also for storing big data cost-effectively and with flexibility, thus allowing for:
- Dropping raw, historical data at first and then creating several downstream models (marts, aggregates, features) from the one source of truth.
- Speeding up the iteration of business logic data science (let’s say, changing the definition of “active customer”) just by modifying the SQL code in version-controlled transformation projects (like debt).
This method is also very suitable for “analytics engineering”: transformations-as-code that are tested and deployed in the same way as software.
The Times When ETL Is Still a Good Idea
There may be a situation where ETL is the only way out:
- Data schema and quality should be strictly enforced even before the warehouse gets the data (e.g. regulated environments).
- If you have a lot of non-SQL heavy transformations (like complex ML feature pipelines, image processing) which are better done outside the warehouse.
In reality, most modern stacks are hybrids: light EL (ingestion into a lake/warehouse) combined with heavy T steps that can be done either in the warehouse (for analytics models) or outside (for ML pipelines).
How to Communicate This to Stakeholders
Connect With Us: WhatsApp
One simple analogy for explaining this on your blog:
- ETL = all cleaning and cutting are done in a non-visible kitchen with no one having tasted or seen the meal.
- ELT = all raw materials are nicely presented and labeled at the buffet, then the different chefs can formulate the dishes on demand.


