

Clustering Algorithms: K‑Means, Hierarchical, and DBSCAN 2026?
Unsupervised learning helps in discovering the hidden structure. Clustering Algorithms groups similar observations without labels perfect for customer segmentation, anomaly detection, and preprocessing.
Connect With Us: WhatsApp
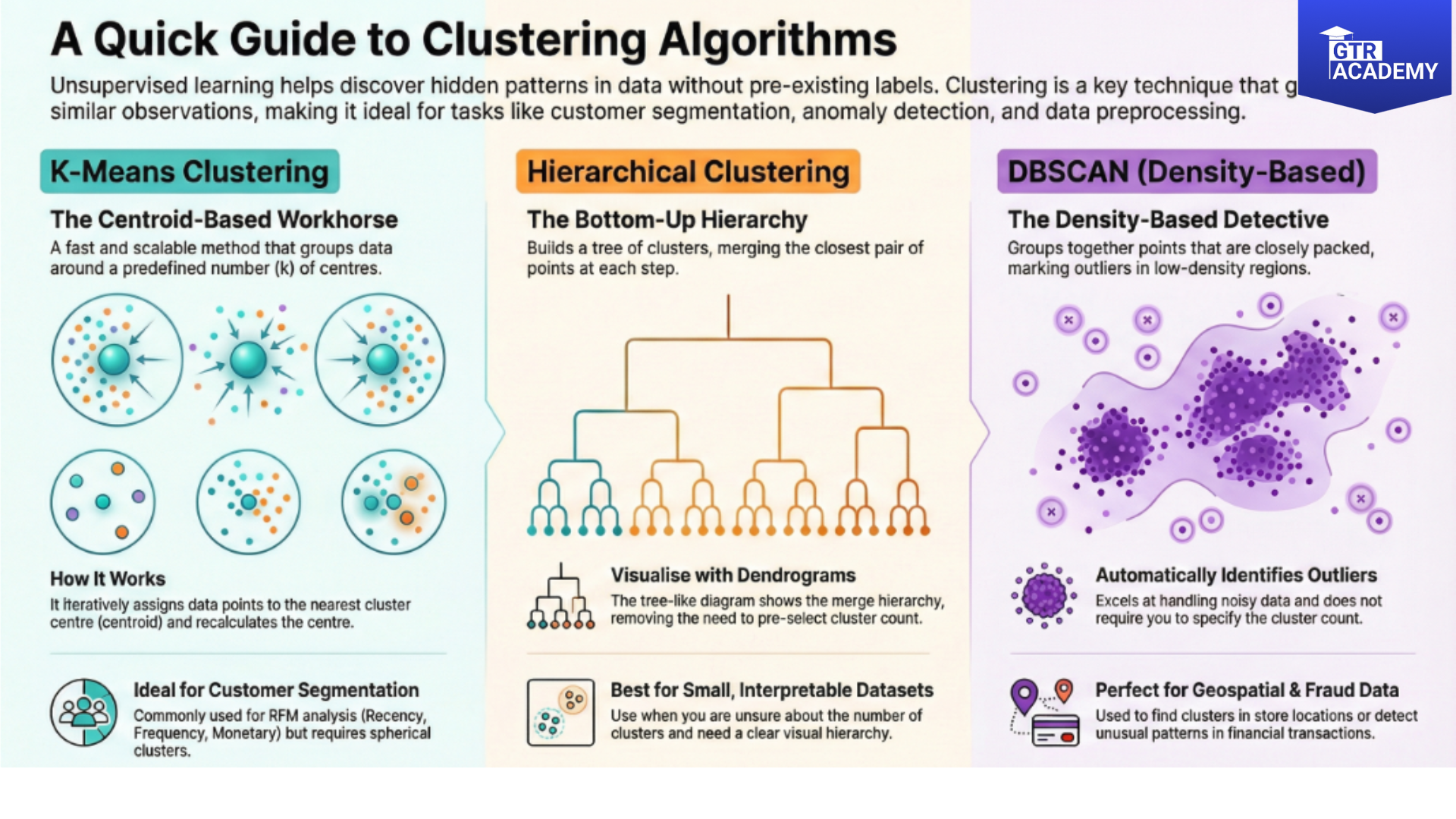
K‑Means: The workhorse
How k-Means works:
- Pick random centroids.
- Assign points to nearest centroid.
- Recalculate centroids as mean of assigned points.
- Repeat → convergence.
Pros: Fast, scalable.
Cons: Need to pick, assumes spherical clusters.
Business use: RFM segmentation (Recency, Frequency, Monetary).
Hierarchical clustering: Dendrograms and no
Agglomerative (bottom‑up):
- Start with each point as cluster.
- Merge closest pairs iteratively.
- Dendrogram shows merge hierarchy.
Use when: Small data, need interpretable hierarchy, unsure about.
DBSCAN: Density‑based, handles outliers
Key ideas:
- Core points: enough neighbors within.
- Border/Noise: outliers.
- No need to specify cluster count.
Perfect for: Geospatial (store locations), fraud (transaction clusters), noisy data.
Customer segmentation example
- Dataset: 5 features (RFM + engagement).
- K-Means (k=4): Value, At-Risk, New, Dormant
- Hierarchical: Confirms structure + sub‑clusters
- DBSCAN: Flags 2% outliers for manual review
- Validate with silhouette score, business logic.
Pro tips:
- Standardize features first.
- Elbow/silhouette for.
- Dimensionality reduction (PCA/t‑SNE) for viz.
Connect With Us: WhatsApp
Try this: Cluster customers by RFM. Target “At‑Risk” with win back campaign, “Value” with upsell.


