

Data Quality and Observability: Why They Matter Even More with GenAI
Since firms are embedding GenAI in additional business workflows, poor, Data Quality no longer results only in ineffective dashboards but also in confidently generated, inaccurate answers at scale. Hence, data quality and observability have become the indispensable bedrock for any viable AI or analytics venture.
Connect With Us: WhatsApp
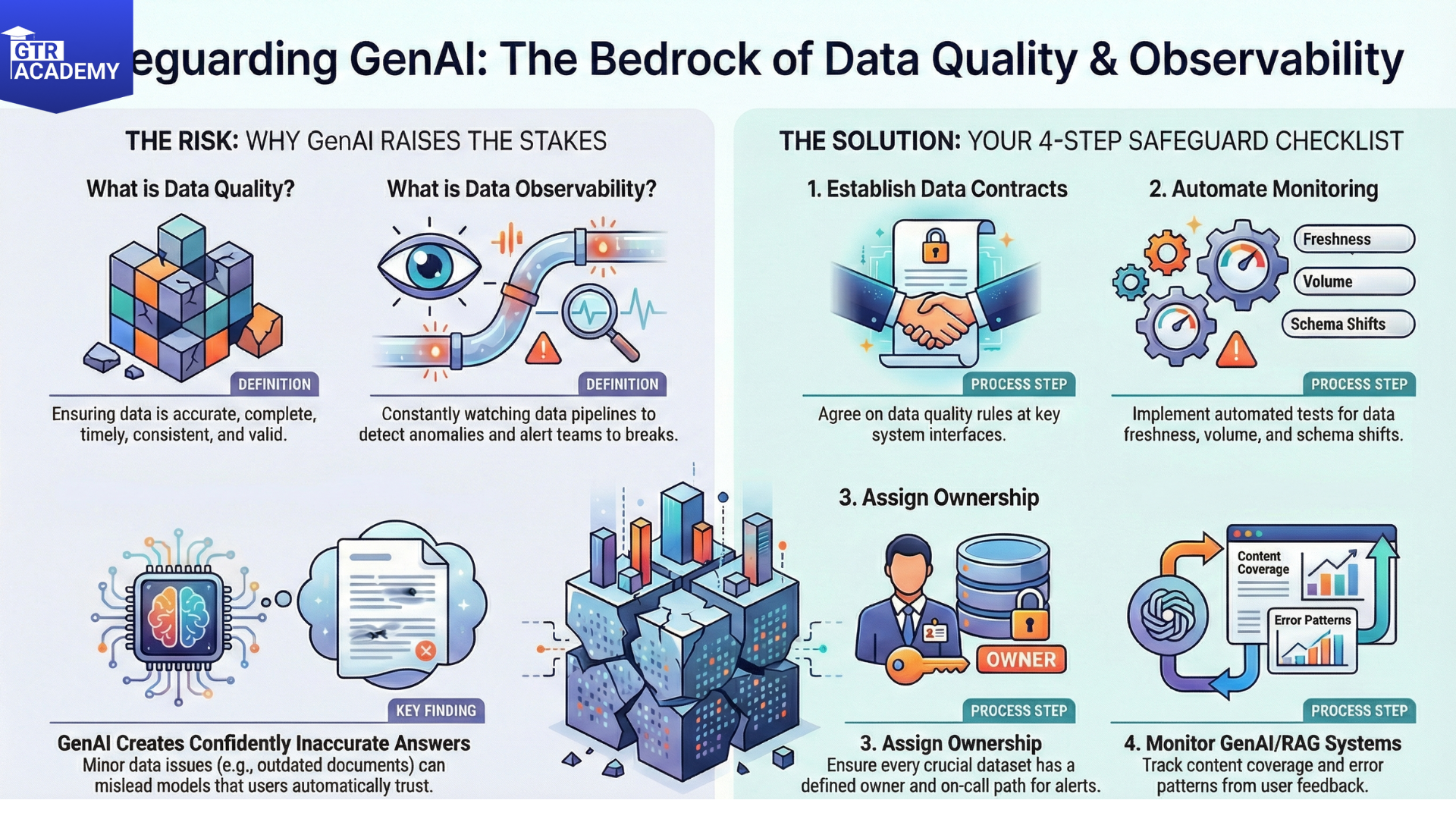
So, what do data quality and observability actually mean?
- Data quality: Making sure that data is accurate, complete, timely, consistent, and valid concerning the given rules (e.g., no negative ages, unique IDs, non, null keys).
- Data observability: Keeping a constant watch on datasets and pipelines to detect volume, schema, distributions, and lineage anomalies, and notify the teams when something breaks.
Both of them are your early warning radar to data issues before these issues snowball into broken reports, mis, trained models, or hallucination, prone RAG systems.
Why GenAI raises the stakes
GenAI systems often:
Use unstructured and semi, structured data from a multitude of sources (like docs, tickets, logs, CRM notes). Depend on retrieval and embeddings where minor data issues (incorrect permissions, outdated content, wrongly labeled docs) can mislead outputs.
Create fluent, convincing, sounding answers that users may automatically trust. This means that:
Out of date or inaccurate documents in your index wrong but confident answers. Secret schema changes in upstream systems corrupted features or broken retrieval. Strong data quality and data observability allow you to see and remedy these issues before they get too big.
Tangible practices to emphasize
You may offer your audience a down, to, earth checklist:
- Agree upon data contracts and quality rules at the main interfaces (for instance, between the source systems and the data warehouse, between the warehouse and feature stores or indexes).
- Put into practice automated tests and monitors for freshness, volume anomalies, schema, and distribution shifts. Connect alerts to ownership: i.e., every crucial dataset/data product should have a defined owner and on, call path.
- As for GenAI/RAG systems, keep an eye on not only usage but also content coverage (what percentage of relevant documents are indexed) and error patterns in user feedback.
- In the next series of articles, we’ll demonstrate how to integrate basic data quality checks and observability in your current analytics stack, as well as what extra signals to monitor once you begin to serve GenAI powered experiences on top of your data.


