Train/ Validation/ Test Splits and Data Leakage in Practice
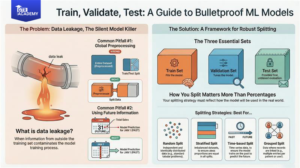 A machine learning model’s effectiveness is heavily reliant on how well its evaluation is conducted. Numerous “excellent” models fail in production because of inadequate data splitting and unnoticed data leakage. This article outlines ways to organize the train/validation/test splits and illustrates what data leakage looks like in actual projects.
A machine learning model’s effectiveness is heavily reliant on how well its evaluation is conducted. Numerous “excellent” models fail in production because of inadequate data splitting and unnoticed data leakage. This article outlines ways to organize the train/validation/test splits and illustrates what data leakage looks like in actual projects.
Why splits matter
If you train and test your model on the same dataset, you will get an inaccurate notion of the model’s correctness that usually fails when you apply it to real-world data. Splits are there to prevent this from happening as they keep aside portions of data that the model is not allowed to see during training.
- Training set: It is employed to adjust the parameters of the model.
- Validation set: It is utilized to tune hyperparameters, compare models, and make design choices.
- Test set: It is used once at the end to provide an estimate of the true performance on the unseen data.
The typical initial point can be 70–80% train, 10–15% validation, and 10–15% test, with the changes made according to the size of the dataset.
Practical splitting strategies
The way you split the data can have a bigger impact than the exact values of the percentages.
- Random split: It is suitable for many tabular problems where rows are independent and identically distributed.
- Stratified split: It guarantees the same class proportions in each split for imbalanced classification (e.g., fraud vs non-fraud).
- Time-based split: For time series or any temporal data, always train on the past and validate/test on the future to simulate the actual deployment.
- Grouped split: When multiple rows correspond to the same entity (user, patient, device), make sure each entity is in only one split so that you do not “peek” at the same entity in both train and test.
In the case of small datasets or when numerous modelling decisions are made, k-fold cross-validation on the training data is often used instead of a single validation split to obtain more reliable results.
What is data leakage?
Data leakage is the situation when information from outside the training process—most often from validation or test sets—unexpectedly gets to model training. That causes extremely optimistic validation/test scores which are far from the real-world performance.
Major forms include:
- Target leakage: Features hold direct or indirect information about the target that would not be available at prediction time.
- Train–test contamination: Validation or test data is used for preprocessing, feature engineering, or model fitting.
Leakage is among the most frequent and serious errors which are made in ML pipelines in practice.
Concrete leakage examples
Here are the scenarios you can refer to in the blog with distinct “wrong vs right” patterns.
- Preprocessing on the whole dataset
- Wrong: You scale, encode, or impute by utilizing the entire dataset and then perform splits.
- Why it leaks: The values for mean, standard deviation, or category frequencies now have information from validation/test data.
- Right: Always split first. Do the fitting of the preprocessing only on the training set, then use those fitted transformers for validation and test.
- Using future information in features
- Wrong: To predict churn at the beginning of January, you use “total tickets in January” as a feature.
- Why it leaks: That info is not there for the prediction time; so it is basically cheating with future data.
- Right: Restrict feature construction to the data that is available up to the prediction time and also splitting should be done chronologically.
- Entity split mistakes
- Wrong: The driver-behavior. model where one driver is found in both train and test.
- Why it leaks: The model identifies driver-specific patterns that result in an artificially high test performance.
- Right: Use a grouped or hash-based strategy to split by driver ID thus each driver will be in only one split.
- Target encoding with leakage
- Wrong: Calculate mean target per category by using the entire dataset before splitting or without proper cross-validation.
- Why it leaks: Encodings indirectly get the labels of the validation/test rows.
- Right: Do target encodings in cross-validation folds or by using only training data and then apply them to validation/test.
A safe pipeline pattern
A pattern that is very difficult to break which you might explain in the article:
- Collect all data into two parts: train and test (and possibly train/validation/test or train + k-fold CV on the train).
- Create a pipeline object comprising preprocessing + the model (for example, in scikit-learn).
- Only training data/folds pipeline fitting; it will manage the fitting of preprocessing steps properly.
- Hyperparameter tuning on validation or by cross-validation.
- After the final decision, performance is evaluated on the test set that has been left completely aside just once.